
브라우저에서 무언가를 처리하기 위해서는 먼저 목적지를 입력해야 한다. 브라우저로 어딘가에 방문하는 방법은 여러 가지다. 주소 막대에 URL을 입력해도 되고, 웹페이지나 다른 앱에서 링크를 클릭(아니면 탭)할 수도 있다. 즐겨찾기 목록에서 하나를 골라 클릭하는 것도 방법이다. 이 모든 것은 결국 내비게이션navigation을 생성하는 것이다. 웹브라우저에서 이뤄지는 사용자 상호작용의 첫 출발은 항상 내비게이션이다. 내비게이션으로부터 일련의 연쇄작용이 촉발되고, 결국 페이지가 로드되기에 이른다.
요청 초기화
조회하려는 페이지의 URL을 브라우저에 입력했을 때, 우리 눈에 보지 않는 곳에서 어떤 일이 일어나는지 살펴보자.
HSTS 검사
첫 번째로, 브라우저는 URL의 스킴scheme이 HTTP(비보안 프로토콜)로 지정되어 있는지 식별한다. HTTP 요청이 맞다면 도메인이 HSTSHTTP Strict Transport Security(HTTP 보안 통신 강제) 목록에 포함되어 있는지 검사한다. HSTS 목록은 두 가지로 구성된다. 하나는 사전 정의된 목록이고, 또 하나는 사용자가 이미 방문한 사이트에서 HSTS가 설정된 것을 모아둔 목록이다. 둘 다 웹브라우저에 저장되어 있다. 브라우저는 접속하려는 호스트가 HSTS에 등재된 경우 URL을 HTTP 대신 HTTPS 버전으로 변경해 요청한다. 그래서 요즘 사용하는 웹브라우저에서는 주소 막대에 http://www.bing.com을 입력해도 https://www.bing.com에 접속되는 것이다.
서비스 워커 검사
두 번째로, 브라우저는 요청을 대신 처리할 서비스 워커가 있는지 확인한다. 이 과정은 사용자가 네트워크 접속이 끊긴 오프라인 상태일 때 특히 중요하다. 서비스 워커는 비교적 최근에 도입된 기능이다. 서비스 워커를 활용하면 #_top사용자의 네트워크 요청(최상위 요청도 포함)을 가로채 스크립트가 제어하는 캐시를 통해 결과를 반환할 수 있다. 그래서 웹사이트가 오프라인 상태에도 작동할 수 있게 된다.
사용자가 페이지를 방문하면 브라우저는 내부 데이터베이스에 URL과 서비스 워커를 매핑해 기록한다. 이것이 서비스 워커의 등록 절차다. 어떤 웹사이트의 서비스 워커가 설치되어 있는지 확인하려면 이 데이터베이스에서 URL을 찾아보면 된다. 사용자가 입력한#_top URL의 서비스 워커가 존재한다면 이 서비스 워커가 요청을 대신 처리해 응답하는 역할을 맡는다. 브라우저에 내비게이션 프리로드Navigation Preload 기능이 탑재돼 있고 웹사이트가 이를 활용하도록 설정해두었다면, 서비스 워커가 요청을 처리하는 것과 별개로 브라우저 또한 본래의 요청을 네트워크로 조회한다. 이렇게 하면 서비스 워커의 부팅이 지연되는 경우에도 웹사이트를 빠르게 로드할 수 있다.
요청을 처리할 서비스 워커가 등록되지 않은 경우(또는 내비게이션 프리로드가 사용되는 경우)에는 브라우저가 네트워크 계층의 작업을 제어한다.
네트워크 캐시 확인
브라우저는 네트워크 계층을 통해 캐시에서 유효기간이 초과하지 않은 응답이 있는지 확인한다. 캐시 제어 정보는 일반적으로 응답 메시지의 Cache-Control 헤더에 정의한다. max-age 값으로 유효기간을 설정하고, no-store 값으로 캐시를 아예 금지하도록 설정할 수도 있다. 물론 네트워크 캐시에 캐시 정보 자체가 없는 경우에는 네트워크 요청이 필요할 것이다. 캐시에 유효한 응답이 있으면 이를 이용해 페이지를 로드할 수 있다. 캐시에 자원이 있기는 한데 유효기간이 초과되었다면 어떻게 될까? 이 경우 브라우저는 요청을 선택적 재유효화 요청으로 변환할 수 있다. 요청 메시지에(요청 메시지 중?) If-Modified-Since 헤더 또는 If-None-Match 헤더에 브라우저가 갖고 있는 자원의 버전 정보를 담아 서버에 알려주는 것이다. 그러면 서버는 HTTP 304(Not Modified)라고 응답함으로써 그 자원이 여전히 유효하다는 사실을 알려주거나 HTTP 200(OK)이라고 응답해 그 자원의 최신 버전을 새로 보내줄 수 있다.
기존 접속 검사
요청하려는 곳의 호스트와 포트가 동일한 네트워크 접속이 이미 이루어져 있다면(동일한 네트워크에 이미 접속됐다면) 새로 접속하는 대신 기존 연결을 계속 사용한다. 접속된 연결이 없다면 브라우저는 DNSDomain Name System(도메인 이름 체계) 조회가 필요한지 확인한다. 지역 DNS 캐시(단말기에 내장돼 있다)를 검색하고, 이 캐시가 유효하지 못하다면 원격 네임서버(인터넷 서비스 제공자ISP가 운영한다)를 조회하는 것이다. 그러면 접속하려는 도메인에 해당하는 IP 주소를 얻을 수 있다.
브라우저가 이후에 접속하게 될 도메인을 예측해 미리 연결해둘 수 있는 경우도 있다. 웹페이지는 자원을 링크하는 태그에 rel=”preconnect”와 같이 리소스 힌트를 입력해둘 수 있다. 이러한 자원 힌트를 어떻게 사용하면 유용할까? 빙Bing의 사용자 검색 결과를 예로 들면, 최상위 항목 몇 개가 가장 방문 가능성이 높을 것이다. 이들의 도메인에 미리 연결해둔다면 사용자가 그 링크를 클릭했을 때 DNS 조회와 접속 설정으로 인한 지연을 줄일 수 있을 것이다.
접속
이제 브라우저는 서버에 접속할 수 있으며, 서버는 클라이언트와 송수신이 가능하게 된다. TLS를 사용하는 경우 서버의 인증서를 확인하기 위한 TLS 핸드셰이크도 수행한다.
요청 전송
접속이 이뤄진 후 가장 먼저 요청하게 될 정보는 최상위 페이지가 될 것이다. 일반적으로 서버가 클라이언트에 HTML 파일을 응답해주게 된다.
응답 처리
브라우저는 응답 데이터를 스트리밍해 받는 동안 분석하고 처리한다. 우선 응답 메시지의 헤더를 확인한다. HTTP 헤더는 HTTP 응답의 일부분으로, 이름과 값으로 이루어진 쌍들을 묶은 것이다. 응답 헤더가 리디렉트redirect(다른 곳으로 전달)를 지시하는 경우(Location 헤더가 한 예이다), 브라우저는 HSTS 검사 단계부터 전체 내비게이션 과정을 다시 시작한다.
서버의 응답이 압축돼 있거나 쪼개져 있다면 브라우저는 압축을 풀거나 덩어리들을 합칠 것이다.
또한 브라우저는 응답 메시지를 읽어들이면서 동시에 네트워크 캐시도 기록하기 시작한다.
그 다음 단계로 브라우저는 응답받는 파일을 올바른 방식으로 해석할 수 있도록 파일의 MIME 유형을 확인한다. 예를 들어 이미지 파일은 그냥 그림으로 읽어들이면 되지만 HTML은 구문을 분석하고 문서의 그래픽을 생성해야 한다. HTML 해석기parser는 응답받은 내용에서 다운로드해야 하는 자원을 가리키는 URL들을 찾아 브라우저가 미리 다운로드를 시작할 수 있도록 하는데, 이는 문서의 그래픽을 생성하는 단계에 이르기도 전에 이루어진다. 이에 관해서는 시리즈의 다음 글에서 더 자세히 다룰 예정이다.
이 지점에서 요청된 URL은 브라우저 방문 기록에 입력되며, ‘뒤로 가기’와 ‘앞으로 가기’ 기능을 이용할 수 있게 된다.
다음 순서도에서 지금까지 다룬 내용을 약간의 세부 내용과 함께 전체적으로 확인할 수 있다.
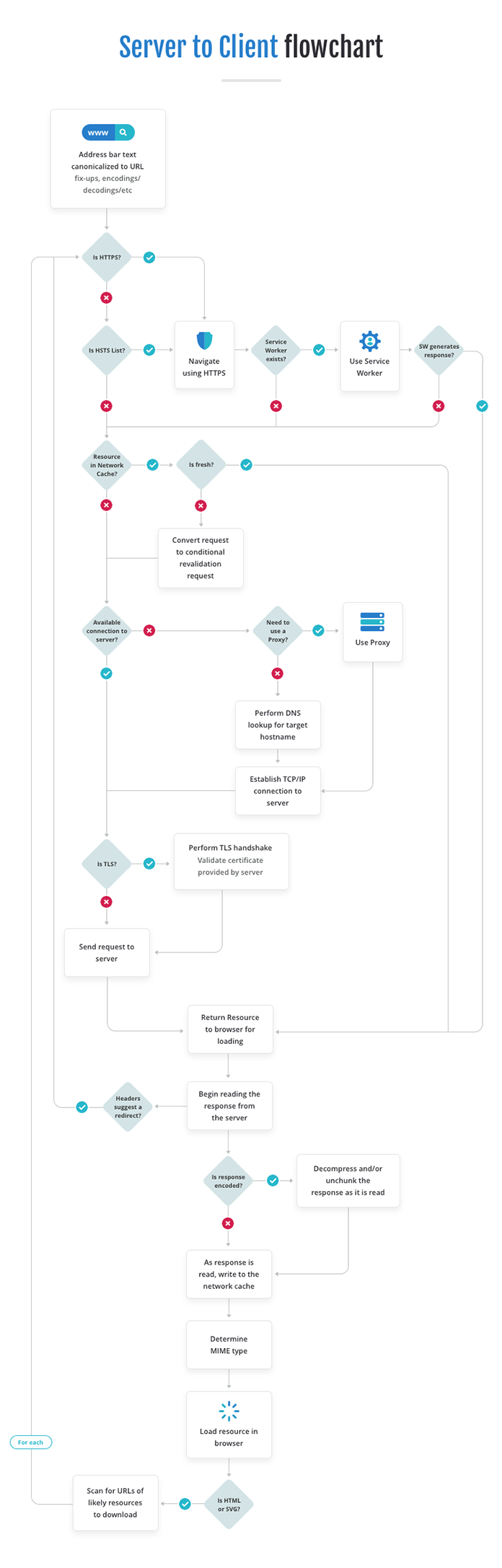
여러분도 알다시피 페이지가 로드되는 동안 요청이 계속 일어난다. 페이지에는 사용자 경험을 증진하는 데 필요한 이미지, 자바스크립트, 스타일시트와 같은 하위 자원들이 많이 포함돼 있기 때문이다. 여기에 더해 이러한 하위 자원들이 다른 자원을 참조하기도 한다. 예를 들어 CSS에서 배경 이미지를 참조할 수 있으며, 자바스크립트에서도 fetch(),import() 또는 AJAX 호출을 통해 다른 자원을 요청할 수 있다. 이를 금지한다면 웹페이지는 복잡한 상호작용 기능을 갖추기 어려울 것이다. 앞의 설명과 순서도에서 봤듯이 각 자원에 대한 요청 역시 브라우저의 캐시 정책에 부분적으로 영향을 받는다.
캐시 처리
앞서 브라우저는 네트워크 캐시를 관리한다고 언급했다. 그래서 이미 다운로드한 자원을 재사용할 수 있는 경우가 많다. 크게 바뀌지 않는 자원에 특히 유리하다. 로고 이미지나 자바스크립트 프레임워크 코드 같은 것이 대표적이다. 이 캐시의 장점을 최대한 살리는 것이 중요하다. 외부 네트워크에 요청해야 할 상당수를 내부 캐시를 사용하는 것으로 대체할 수 있기 때문이다. 그러면 무겁고 감춰져 있는 연산을 최소화할 수 있으며 페이지 로드 시간을 단축할 수 있다.
물론 네트워크 캐시를 무한히 사용할 수는 없다. 저장할 수 있는 개수와 기한 모두 제약이 있다. 하지만 웹사이트에도 이에 대한 발언권이 주어진다. 응답 메시지의 Cache-Control 헤더를 이용해 브라우저의 캐시 방식을 제어할 수 있다. 자원이 항상 달라지는 특정한 경우에 한해 브라우저가 특정 항목을 캐시하지 않도록 금지(Cache-Control: no-store)하는 것도 조심스럽게 지시할 수 있다. 또 다른 경우로 특정 URL의 자원이 절대 변하지 않는다면 브라우저가 자원을 무기한으로 캐시하도록 지시(Cache-Control: immutable)할 수도 있다. 이런 경우에는 해당 자원이 다른 버전으로 변경될 때 기존 자원을 변경하기보다는 새 URL로 새 자원을 가리키도록 하는 편이 옳다. 안 그러면 변경 후에도 기존 URL의 캐시가 계속 사용될 것이기 때문이다.
물론 브라우저에서 사용할 수 있는 캐시는 네트워크 캐시만이 아니다. 자바스크립트를 통해 활용할 수 있는 프로그래밍용 캐시도 있다. 특히 앞서 소개한 서비스 워커의 사례에서 서비스 워커가 최상위 페이지에 대한 초기 요청을 가로채 캐시된 항목을 반환한다고 했다. 이때 사용하는 캐시는 프로그래밍용 캐시이며, 이 활용법을 웹사이트가 정의할 수 있다. 브라우저가 어떤 항목을 캐시하고 언제 사용할 것인지에 관해 웹사이트가 더 많은 제어권을 가질 수 있어서 유용하다. 이러한 캐시는 자원의 출처에 종속된다. 도메인마다 캐시 샌드박스를 가지며, 이는 다른 도매인의 캐시와 분리된 채 제어된다.
출처 모델
출처origin는 스킴(프로토콜), 호스트 이름, 포트를 묶은 것이다. 예를 들어 https://www.bing.com:443은 프로토콜이 HTTPS이고, 호스트 이름이 www.bing.com이고, 포트가 443이다. 이 가운데 하나라도 다르다면 그것은 출처가 다른 것이다. 예를 들어, https://images.bing.com:443과 http://www.bing.com:80은 서로 다른 출처이다.
출처는 브라우저에서 중요한 개념으로, 데이터들을 서로 분리해 관리하는 기준이 된다. 브라우저는 보안을 위해 대부분의 경우 동일 출처same-origin 정책을 적용한다. 동일 출처 정책이란 한 출처에서 다른 출처의 데이터에 접근하지 못하도록 하며, 서로 동일한 출처에서만 정보 접근이 가능하도록 하는 것이다. 예를 들어, 앞서 캐시 사례에서 살펴본 https://images.bing.com:443과 http://www.bing.com:80은 서로의 프로그래밍용 캐시에 접근할 수 없다.
bing.com이 microsoft.com에서 자바스크립트 파일을 읽어들이려고 하는 경우, 이는 교차 출처cross-origin 자원 요청에 해당하며, 브라우저는 동일 출처 정책에 따라 이를 금지할 것이다. 이를 허용하기 위해서는 microsoft.com이 bing.com에 협조해줘야 한다. microsoft.com이 CORS(Cross-Origin Resource Sharing: 교차 출처 자원 공유) 헤더에서 bing.com이 자바스크립트 파일을 로드할 수 있도록 설정하면 된다. CORS 헤더를 올바르게 설정해 브라우저가 교차 출처 자원 요청을 적절하게 처리할 수 있도록 하는 것이 장려된다.
결론
이 글에서 여러분은 서버에서 클라이언트로 가는 여정과 그 사이의 세부 사항들을 자세히 알아봤다. 그 다음 글 “HTML 태그에서 DOM으로”에서는 웹페이지를 로드하는 과정에 대해 자세히 배워볼 것이니 기대하시라.

제레미 키스의 『서비스 워커로 만드는 오프라인 웹사이트』
서비스 워커는 그동안 우리가 사용했던 그 어떤 도구보다 강력하다. 서비스 워커를 이용하면 네트워크 요청을 직접 제어할 수 있다. 네트워크 요청을 보낼지 말지도 결정할 수 있다. 즉 웹 브라우저가 요청을 보내기 전에 뭔가 작업하도록 지시할 수 있는 도구가 바로 서비스 워커다. 이 책은 진정으로 회복력 있는 웹사이트를 어떻게 디자인해야 하는지 보여준다. 마침내 우리는 변덕스럽고, 믿지 못할 네트워크 환경에서도 차질 없이 작업할 수 있는 접근성 높은 해결 방법을 찾은 것이다.